|
Premium
Datum registracije: Jul 2012
Lokacija: vk+
Postovi: 14,584
|
Evo neke interpretacije zen dieshota.
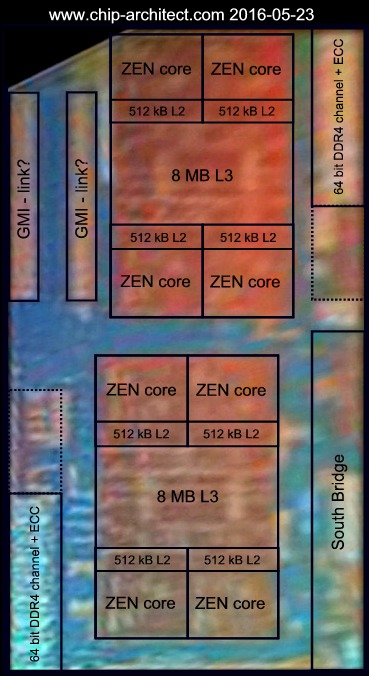
Citiraj:
Harlan Sur
So how should we think about, and we'll about the Zen architecture in a few minutes, but you've obviously got the existing Opteron architecture. How do you think, Mark, as it relates to the JV? And the initial technical engagements and product engagements is you are going to be based off of the current generation Opteron architecture or are you going to be focusing the JV more on the Zen-based architecture?
Mark Papermaster
Well, the JV will be announcing the details as they proceed. So the deal is closed, its up and running, and you'll see more details coming. Clearly from our new architectures going forward is, as we announced actually a year ago at our financial Analyst Day, we said that we would have the new Zen core, with a significant performance bump, that we'd be sampling this year. It would be in full year production in next year, and we of course remain right on track to what we put out there. So quite an excellent execution.
Harlan Sur
On the Zen architecture, your next-generation compute architecture, maybe highlight some of the key changes in this new architecture. You talked a little bit about the schedule, but go into a little bit more detail in terms of when do we see Zen-based products hitting the markets?
Mark Papermaster
Absolutely. So what we did with Zen, it is truly a ground up new design. It leverage the deep experience we had in 64-bit x86, which of course, AMD was the pioneer in the industry with this technology. But when I say from scratch design, I mean really retooling how you get performance and actually very high performance.
And so we went about it with really three facets. You have to basically modify the execution engines to tune them up. We tune them up in a way to basically improve the efficiency of the processing. We've tuned up how you cache, right, so how instructions can install, if you don't have the right the local cache instructors, so we tuned up our cache sub-system.
And then you have to feed those engines and so we tuned up our IO and memory. And so this was just roll up the sleeves, hard-nosed microprocessor engineering to get that kind of bump, where you have 40% instruction per clock versus our current generation, which is shipping in Bristol Ridge. That's huge and it's a result of that hard-nosed engineering.
Harlan Sur
So in terms of the rollout, I think the team has said high-end desktops will be rolled out first with Zen architecture towards the end of this year. What follows on from that? Do you then go after the high-end notebook segment of the market or you have talked a lot about servers. I think your customers are waiting for a competitive server platform as well. So how should we think about beyond desktops, what gets rolled out next?
Mark Papermaster
Well, you think about the kind of investment we made. We started Zen several years ago, right. That's what it takes when you do a brand new design. So it's right on track. And when you have that kind of jump in performance, we're going to prioritize the markets that are performance hungry. So we'll be in, in order of high performance desktops, followed by server. And then what we'll do is as we have done in the past, we then trickle that into our client compute markets across the mainstream, across the notebook markets. So it's very much on that type of rollout path.
Harlan Sur
So should we anticipate something like desktop end of this year, server first half of next year and then client compute mainstream as we roll through the remainder of 2017? Is that kind of how we think about it?
Mark Papermaster
Well, the order is correct. We haven't release these specific times. But again, we're on track, what we said is we'll be sampling to priority customers at the end of this quarter, on track there. We said first full year of our production ship next year right on track, and again, in that order of desktop, server and the client compute.
Harlan Sur
And I know, Lisa mentioned this, you just mentioned this as well that you are sampling, will be sampling, are sampling, the architecture now. How are conservations with OEMs and cloud providers coming along, as it relates to early look at Zen and their usage of Zen both for PCs and servers?
Mark Papermaster
Well, there's been a lot of pull, right. The market wants competition back in the space. And so as such we've been actually having dialogue along the way. So the good news about this design is it's customer-influenced. Our customers have told us what are they looking for, what are the features that they need, so this design can solve their problems that they're tacking on a day-to-day basis. So it's been an ongoing dialogue.
And when you look at the piece that we really like about this is just the fact that it's dropping in an x86 ecosystem. So when we deliver this value, when we incorporate the kind of features our customers have talked about, and you leverage the fact that we've been in x86 some time, so we're very experienced at what's the software integration that we need, what's the memory in iOSs and how do you get this to drop right in to harbor subsystems, which are out there in the industry today.
We've been there, we've done that, we're leveraging that experience. So it's actually a very smooth engagement with our OEMs and ODMs. It's about us getting back with the high-performance competitiveness. We know this ecosystem.
Harlan Sur
So we can't have a discussion about compute architecture without discussion on Moore's Law, manufacturing technology. Obviously, Intel is ramping 40-nanometer now (14nm). They plan to move to 10-nanometer, kind of second half of next year. Do the competitive dynamics change again in favor of Intel, when they move to 10-nanometer? Why or why not?
Mark Papermaster
Well, let's step back, because you got to really have some context when you look at these semiconductor nodes and where it's been. Ourselves, and our other competitors that are fabless have had historically a significant gap. In fact up to 2 nodes of gap versus our competitor. What's really significant about this transition of FinFET is that the gap has shrunk dramatically. So when you look at our introduction of FinFET, Intel's out there on 40-nanometer (14nm) and they delayed 10-nanometer into second half of next year.
Harlan Sur
Correct.
Mark Papermaster
So that is a tremendous opportunity. We expect them to stay focused on manufacturing technology. But the fact is the physics are such that it's impossible for the previous pace of semiconductor enhancements of keeping the costs down, keeping the performance up, the power going down at every generation, it's slowing, that's when you hear Moore's Law slowing, it's not going away by any means, it's slowing and it's becoming more expensive on the node transitions.
And so for us, as a fabless company, it's a tremendous opportunity because the foundries are executing well, they've closed the gap as they transition to FinFET. And when you look at their plans, and they've been public about those plans, they intend to keep that gap narrow or eliminated and its very exciting opportunity for us. We're taking advantage of it right now. Polaris, as it launches this year and as we roll out the new Zen Core across the markets that we described earlier, tremendous opportunity.
Harlan Sur
I've always thought about as we do get a slowing of Moore's Law that there is two ways that you can improve performance, right. One is just brute force moving down Moore's Law curve, and the other way is more elegant design techniques to extract performance. And so how does the AMD team kind of strike a balance between the two?
Mark Papermaster
We've always had to be a bit more nimble, because frankly being the guy that has to run faster you have to be more efficient, we're going to run with a more aggressive front, we've had to invest significantly on the design side of getting performance at lower energy.
So Ruth mentioned a moment ago Bristol Ridge that we're shipping this year, so that's our seventh generation APU and it's a huge step on a commitment we made to have a 25x reduction in energy, and so therefore, 25x improvement in energy efficiency from 2014 to 2020 in the mobile space.
And this introduction of the sixth and seventh-generation have us right on track of that curve. And we've done it by design. We have a more efficient building blocks or cells at a very, very high density. The power management techniques and controllers we built in are quite advance, and so we've had to really focus on design for performance at very miserly energy consumption and we carry that forward into the Zen Core.
So we leverage that FinFET, we leverage that new design approach for performance, but we didn't forget any of the power management that we've been practicing the last several years to keep us on that very public commitment we put out there for energy efficiency. So it is very much about being more nimble on design and then leveraging that foundry roadmap that I mentioned just a moment ago.
|
Zadnje izmijenjeno od: Manuel Calavera. 28.05.2016. u 00:34.
|